Adressduplikate in Excel 2026: Warum 80% unentdeckt bleiben
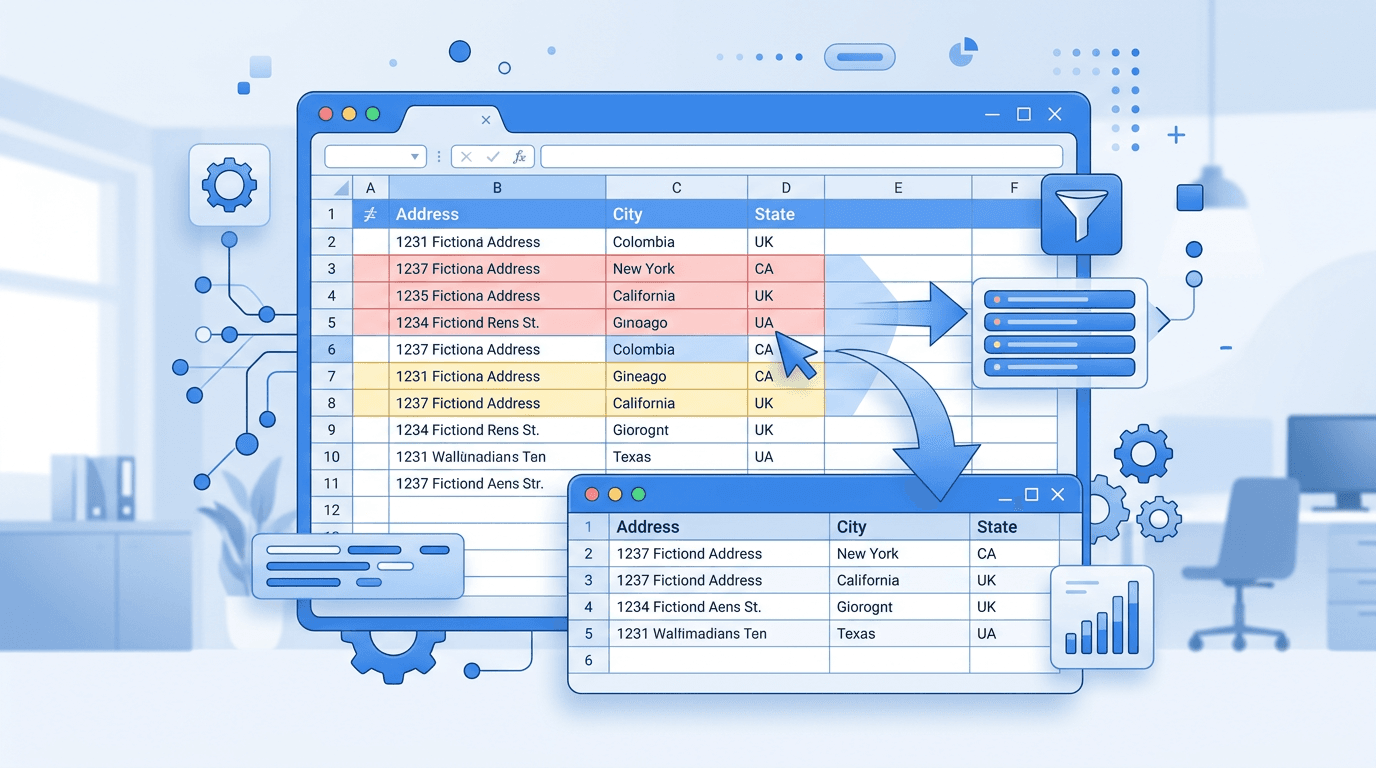
Das Problem: Excel versagt bei realen Adressdaten
Sie öffnen Ihre Excel-Datei, nutzen die Funktion "Duplikate entfernen" und denken, die Arbeit ist getan. Doch die Realität ist häufig anders. Excel erkennt viele Duplikate gar nicht – und das kostet Geld.
Ein Vertriebler versendet im nächsten Monat das gleiche Angebot an den gleichen Kunden, weil Excel Dr. Max Müller und Mueller, Max nicht als identisch erkannt hat. Eine Marketingkampagne wird an Haushalte mehrfach versendet, weil unterschiedliche Schreibweisen in Excel als verschiedene Personen behandelt werden. Das Ergebnis: Verschwendete Budgets, verärgerte Kunden, beschädigte Markenreputation.
Der Grund liegt in der Art, wie Excel Duplikate erkennt: exakte Übereinstimmung. Und in der realen Welt gibt es keine exakten Übereinstimmungen.
Warum Excel scheitert: 5 typische Szenarien
1. Tippfehler und Schreibvarianten
Excel ist unerbittlich: Meier, Meyer und Maier werden als drei verschiedene Personen behandelt.
Meier, Horst | Hauptstraße 12, 70001 Stuttgart
Meyer, Horst | Hauptstr. 12, 70001 Stuttgart
Maier, Horst | Hauptstrasse 12, 70001 Stuttgart
Für Excel sind das drei Einträge. In der Realität ist es eine Person. Der Tippfehler entsteht durch:
- Deutsche Schreibweisen (ei vs. ai)
- Schnelles Tippen oder Scanning von Dokumenten
- OCR-Fehler bei digitalisierter Post
- Unterschiedliche Datenquellen
Ein Vertriebler könnte alle drei kontaktieren – und verschießt damit seine Chancen auf einen echten Erstkontakt.
2. Titel und Anredefehler
Professionelle Adressen enthalten oft Titel:
Dr. Max Müller
Doktor Max Müller
Prof. Dr. Max Müller
M. Müller (mit Initialen)
Excel wird diese Variationen nicht zusammenbringen. In Ihrer Kampagne landen dann mehrere Anschreiben an die gleiche Person – sie erhalten "Dr. Max Müller" einmal als "Sehr geehrter Dr. Müller" und einmal als "Lieber Max". Das wirkt nicht nur unprofessionell, es beschädigt Ihr Image einer organisierten Abteilung.
3. Umlaute und Sonderzeichen
Deutsche Umlaute sind tückisch:
Müller
Mueller
Müller (mit UTF-8-Encoding-Fehler)
MULLER (alles großgeschrieben)
Je nachdem, wie die Daten importiert wurden, können Excel und andere Tools diese unterschiedlich behandeln. Besonders schlimm: Ältere Import-Prozesse können Umlaute zerstören – ü wird zu u, ä zu a.
4. Reihenfolge von Name und Vorname
Menschen erfassen Adressen unterschiedlich:
Max Müller
Müller, Max
Müller Max
M. Müller
Excel wird nie erkennen, dass alle vier die gleiche Person sind. Bei internationalen Datenquellen (UK-Format "Last, First" vs. deutsche "First Last") wird es noch schlimmer.
5. Leerzeichen und Sonderzeichen
Ein Extra-Leerzeichen, ein Tab statt Space, oder Interpunktion:
Müller, Max
Müller, Max (zwei Leerzeichen)
Müller,Max (kein Leerzeichen)
Excel behandelt diese als unterschiedlich. Und wenn Sie per VLOOKUP nach einem Namen suchen, scheitert die Formel lautlos.
Der finanzielle Schaden im Überblick
Unterschätzen Sie nicht, was falsche Duplikatverwaltung kostet:
Redundante Mailings: Bei 50.000 Kontakten mit durchschnittlich 15% Duplikaten sind das 7.500 zusätzliche Mailings. Bei € 0,30 pro Brief: € 2.250 verschenkt.
Vertriebseffizienz: Ein Außendienstmitarbeiter verbringt Zeit mit Datenpflege statt mit Verkauf. Wenn 10% eines 40h-Wochen-Vertriebs in Excel-Duplikat-Bereinigung geht: € 400/Woche verloren (bei €50/h Kostendeckung).
Kundenbeziehungen: Mehrere Kontaktversuche wirken unprofessionell oder aufdringlich. Manche Kunden löschen Sie aus dem Verteiler – auch wenn der erste Kontakt gut war.
Kampagnen-ROI: Ihre Conversion-Metriken werden verfälscht. Sie messen 2,5% Konversionsrate, weil der gleiche Kunde 3x gezählt wurde. Die echte Rate ist 0,8%. Falsche Geschäftsentscheidungen sind die Folge.
Wie professionelle Deduplication funktioniert: Fuzzy Matching
Das Gegenteil von "exakte Übereinstimmung" ist Fuzzy Matching – ungefähre Übereinstimmung basierend auf Ähnlichkeit. Einen umfassenden Überblick über die verschiedenen Algorithmen und deren Einsatz bei Adressdaten finden Sie in unserem Artikel zum Fuzzy Matching bei Adressen.
Das Prinzip:
-
Levenshtein-Distanz: Ein Algorithmus berechnet, wie viele Änderungen nötig sind, um einen String in einen anderen umzuwandeln. "Müller" → "Mueller" braucht nur eine Änderung (ü → ue), also hohe Ähnlichkeit.
-
Gewichtung von Feldern: Nicht alle Felder sind gleich wichtig. Unterschiede im Vornamen sind weniger kritisch als Unterschiede in der Adresse. Systeme wie ListenFix verwenden KI, um relevante Unterschiede zu erkennen.
-
Kontextuelle Intelligenz: Wenn Vorname, Nachname und Hausnummer ähnlich sind, aber die Straße sich unterscheidet – wurde die Person umgezogen oder ist es ein Duplikat? Das System berücksichtigt solche Szenarien.
-
Mehrsprachige Regeln: Umlaute, Sonderzeichen, Namensreihenfolge-Variationen werden regelbasiert normalisiert, bevor der Vergleich startet.
Das Ergebnis: ListenFix erkennt durch Fuzzy Matching deutlich mehr Adressduplikate als die Standard-Funktionen von Excel.
Ein reales Beispiel
Nehmen Sie diesen Datensatz:
Eintrag 1: Dr. Max Müller, Hauptstr. 12, 70001 Stuttgart
Eintrag 2: Max Mueller, Hauptstrasse 12, 70001 Stuttgart
Eintrag 3: Prof. Dr. M. Müller, Hauptstraße 12, 70001 Stuttgart
Excel Duplikat-Funktion: Erkennt 0 Duplikate. Alle werden beibehalten.
ListenFix mit Fuzzy Matching: Erkennt alle drei als identische Person. Wenn die Haushaltserkennung aktiviert ist, wird nur ein Eintrag behalten – welcher, bestimmen Ihre Prioritätsregeln. Die anderen beiden werden automatisch als Duplikate entfernt. Das System hat erkannt:
- Unterschiedliche Titel (Dr., Prof. Dr.) sind für die Identifikation irrelevant
- „Mueller" und „Müller" sind Varianten des gleichen Namens (Umlaut-Normalisierung)
- Unterschiedliche Schreibweisen der Straße (Str./Straße/Strasse) werden normalisiert
- Die Kombination aus Name, Straße und Postleitzahl ist eindeutig
Statt drei Briefe an die gleiche Person zu senden, geht nur noch einer raus – das spart Porto, Material und schützt Ihre Kundenbeziehung.
Household-Merging: Noch eine Liga darüber
Ein weiterer Layer ist das Household-Merging: Das System erkennt, dass mehrere Personen in einem Haushalt leben:
Müller, Max | Hauptstr. 12, 70001 Stuttgart
Müller, Petra | Hauptstr. 12, 70001 Stuttgart
Statt zwei Anschreiben an die gleiche Adresse zu versenden, schicken Sie nur eines – und sparen Porto, Material und wirken professioneller.
Das Besondere: Prioritäten definieren
Was ListenFix von einfacher Duplikat-Erkennung unterscheidet: Sie können über Prioritätsregeln genau steuern, wer die Sendung im Haushalt erhalten soll.
Ein typisches Beispiel aus dem Dialogmarketing: Bei einem Versandhaus soll immer die Dame des Hauses die Katalog-Sendung erhalten – nicht der Ehepartner. Mit ListenFix definieren Sie einfach die Priorität „Weiblich bevorzugt", und das System wählt automatisch Petra Müller als Empfängerin aus. Max Müller wird als Haushaltsduplikat erkannt und aus der Versandliste entfernt.
Weitere Prioritäts-Beispiele:
- Geschlecht bevorzugen: „Immer die Dame des Hauses" oder „Immer der Herr des Hauses"
- Titel bevorzugen: „Person mit akademischem Titel bevorzugen" (z.B. Dr. vor nicht-Dr.)
- Code-Priorität: „Kunden mit Code VDI vor VDA bevorzugen" – ideal für Berufsverband-Mailings
Das Ergebnis: Aus zwei oder drei Einträgen pro Haushalt wird genau der eine richtige Empfänger – vollautomatisch, regelbasiert und reproduzierbar.
Wann Sie Excel nicht verwenden sollten
Benutzen Sie Excel-Duplikat-Funktionen nur, wenn:
- Sie weniger als 1.000 Einträge haben
- Die Daten sauberer Eingabe folgen (keine Tippfehler, einheitliche Formate)
- Kosten für Fehler minimal sind (z.B. interne Listen, nicht für Mailings)
Für alles andere – Kundenlisten, Mailings, CRM-Daten, Lead-Listen – ist Excel unzureichend.
Die Lösung: Professionelle Deduplication
Systeme wie ListenFix bieten:
✓ Fuzzy Matching mit KI: Erkennt echte Duplikate, nicht nur exakte Übereinstimmungen ✓ Haushalts-Merging: Verhindert Mehrfach-Mailings an eine Familie ✓ 100% Offline: Ihre Daten verlassen nie Ihren Computer (GDPR-konform) ✓ Geschlechts-Erkennung: Automatische Anrede-Bestimmung aus Vornamen ✓ Einmalig oder Abo: € 69 einmalig (Starter) oder € 99/Monat (Professional)
Der ROI ist schnell erreicht. Schon bei 10.000 Kontakten und nur 5% vermeintliche Duplikate sparen Sie kosten für redundante Mailings ein.
Warum sich der Umstieg lohnt
Excel ist ein Werkzeug für Tabellen, nicht für intelligente Datenbereinigung. Die Grenzen sind klar: Es kann nur exakt gleiche Einträge erkennen. In der realen Welt, mit Tippfehlern, Umlauten, Titelabweichungen und verschiedenen Formaten, ist das einfach nicht genug.
Professionelle Deduplication mit Fuzzy Matching ist nicht Luxus – sie ist notwendig, um:
- Kosten zu sparen (Porto, Versand, Verarbeitungszeit)
- Kundenbeziehungen zu schützen (keine redundanten Kontakte)
- Datenqualität zu verbessern (echte Insights statt verzerrter Metriken)
Wenn Sie täglich mit Adressen arbeiten – es ist Zeit für eine bessere Lösung.
Direkt zur Lösung: Wie Fuzzy Matching in der Praxis funktioniert, mit Vorher/Nachher-Beispielen und einer 14-Tage-Testversion, sehen Sie auf der Seite Adressdaten bereinigen mit ListenFix.
Adressen bereinigen — jetzt testen
ListenFix erkennt per Fuzzy Matching deutlich mehr Duplikate als Excel. 100% offline, DSGVO-konform.
Kostenlos testen